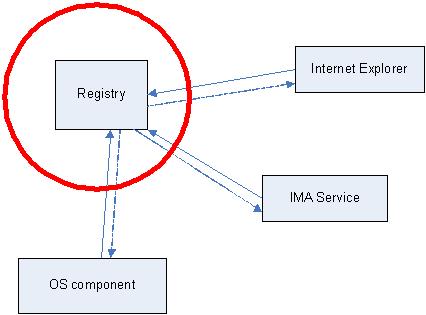
The most important pattern that is used for problem identification and resolution is Stack Trace. Consider the following fragment of !analyze -v output from w3wp.exe crash dump:
STACK_TEXT:
WARNING: Frame IP not in any known module. Following frames may be wrong.
1824f90c 5a39f97e 01057b48 01057bd0 5a3215b4 0x0
1824fa50 5a32cf7c 01057b48 00000000 79e651c0 w3core!ISAPI_REQUEST::SendResponseHeaders+0x5d
1824fa78 5a3218ad 01057bd0 79e651c0 79e64d9c w3isapi!SSFSendResponseHeader+0xe0
1824fae8 79e76127 01057bd0 00000003 79e651c0 w3isapi!ServerSupportFunction+0x351
1824fb0c 79e763a3 80000411 00000000 00000000 aspnet_isapi!HttpCompletion::ReportHttpError+0x3a
1824fd50 79e761c3 34df6cf8 79e8e42f 79e8e442 aspnet_isapi!HttpCompletion::ProcessRequestInManagedCode+0x1d1
1824fd5c 79e8e442 34df6cf8 00000000 00000000 aspnet_isapi!HttpCompletion::ProcessCompletion+0x24
1824fd70 791d6211 34df6cf8 18e60110 793ee0d8 aspnet_isapi!CorThreadPoolWorkitemCallback+0x13
1824fd84 791d616a 18e60110 00000000 791d60fa mscorsvr!ThreadpoolMgr::ExecuteWorkRequest+0x19
1824fda4 791fe95c 00000000 8083d5c7 00000000 mscorsvr!ThreadpoolMgr::WorkerThreadStart+0x129
1824ffb8 77e64829 17bb9c18 00000000 00000000 mscorsvr!ThreadpoolMgr::intermediateThreadProc+0x44
1824ffec 00000000 791fe91b 17bb9c18 00000000 kernel32!BaseThreadStart+0x34
Ignoring the first 5 numeric columns gives us the following trace:
0x0
w3core!ISAPI_REQUEST::SendResponseHeaders+0x5d
w3isapi!SSFSendResponseHeader+0xe0
w3isapi!ServerSupportFunction+0x351
aspnet_isapi!HttpCompletion::ReportHttpError+0x3a
aspnet_isapi!HttpCompletion::ProcessRequestInManagedCode+0x1d1
aspnet_isapi!HttpCompletion::ProcessCompletion+0x24
aspnet_isapi!CorThreadPoolWorkitemCallback+0x13
mscorsvr!ThreadpoolMgr::ExecuteWorkRequest+0x19
mscorsvr!ThreadpoolMgr::WorkerThreadStart+0x129
mscorsvr!ThreadpoolMgr::intermediateThreadProc+0x44
kernel32!BaseThreadStart+0x34
or in general we have something like this:
moduleA!functionX+offsetN
moduleB!functionY+offsetM
...
...
...
Sometimes function names are not available or offsets are very big like 0×2380. If this is the case then we probably don’t have symbol files for moduleA and moduleB:
moduleA+offsetN
moduleB+offsetM
...
...
...
Usually there is some kind of a database of previous issues we can use to match moduleA!functionX+offsetN against. If there is no such match we can try functionX+offsetN, moduleA!functionX or just functionX. If there is no such match again we can try the next signature, moduleB!functionY+offsetM, and moduleB!functionY, etc. Usually, the further down the trace the less useful the signature is for problem resolution. For example, mscorsvr!ThreadpoolMgr::WorkerThreadStart+0x129 will probably match many issues because this signature is common for many ASP.NET applications.
If there is no match in internal databases we can try Google. For our example, Google search for SendResponseHeaders+0x5d gives the following search results:
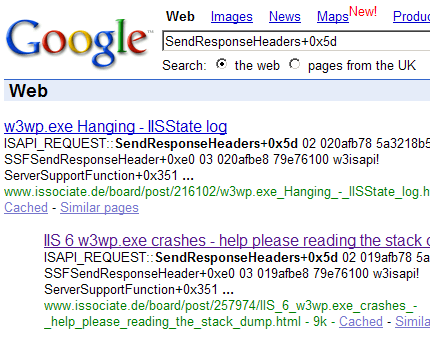
Browsing search results reveals the following discussion:
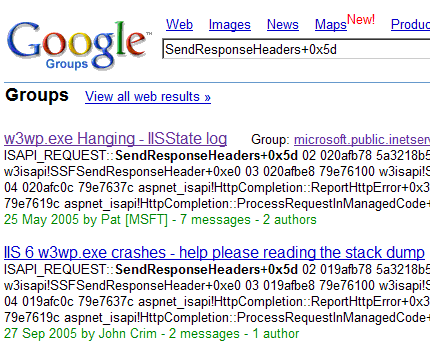
http://groups.google.com/group/microsoft.public.inetserver.iis/ browse_frm/thread/34bc2be635b26531?tvc=1
which can be found directly by searching Google groups:
Another example from BSOD complete memory dump. Analysis command has the following output (stripped for clarity):
MODE_EXCEPTION_NOT_HANDLED (1e)
This is a very common bugcheck. Usually the exception address pinpoints the driver/function that caused the problem. Always note this address as well as the link date of the driver/image that contains this address.
Arguments:
Arg1: c0000005, The exception code that was not handled
Arg2: bff90ca3, The address that the exception occurred at
Arg3: 00000000, Parameter 0 of the exception
Arg4: 00000000, Parameter 1 of the exception
TRAP_FRAME: bdf80834 -- (.trap ffffffffbdf80834)
ErrCode = 00000000
eax=00000000 ebx=bdf80c34 ecx=89031870 edx=88096928 esi=88096928 edi=8905e7f0
eip=bff90ca3 esp=bdf808a8 ebp=bdf80a44 iopl=0 nv up ei ng nz na po nc
cs=0008 ss=0010 ds=0023 es=0023 fs=0030 gs=0000 efl=00010282
tsmlvsa+0xfca3:
bff90ca3 8b08 mov ecx,dword ptr [eax] ds:0023:00000000=????????
Resetting default scope
STACK_TEXT:
bdf807c4 80467a15 bdf807e0 00000000 bdf80834 nt!KiDispatchException+0x30e
bdf8082c 804679c6 00000000 bdf80860 804d9f69 nt!CommonDispatchException+0x4d
bdf80838 804d9f69 00000000 00000005 e56c6946 nt!KiUnexpectedInterruptTail+0x207
00000000 00000000 00000000 00000000 00000000 nt!ObpAllocateObject+0xe1
Because the crash point tsmlvsa+0xfca3 is not on the stack trace we use .trap command:
1: kd> .trap ffffffffbdf80834
ErrCode = 00000000
eax=00000000 ebx=bdf80c34 ecx=89031870 edx=88096928 esi=88096928 edi=8905e7f0
eip=bff90ca3 esp=bdf808a8 ebp=bdf80a44 iopl=0 nv up ei ng nz na po nc
cs=0008 ss=0010 ds=0023 es=0023 fs=0030 gs=0000 efl=00010282
tsmlvsa+0xfca3:
bff90ca3 8b08 mov ecx,dword ptr [eax] ds:0023:00000000=????????
1: kd> k
*** Stack trace for last set context - .thread/.cxr resets it
ChildEBP RetAddr
WARNING: Stack unwind information not available. Following frames may be wrong.
00000000 bdf80afc tsmlvsa+0xfca3
89080c00 00000040 nt!ObpLookupObjectName+0x504
00000000 00000001 nt!ObOpenObjectByName+0xc5
c0100080 0012b8d8 nt!IopCreateFile+0x407
c0100080 0012b8d8 nt!IoCreateFile+0x36
c0100080 0012b8d8 nt!NtCreateFile+0x2e
c0100080 0012b8d8 nt!KiSystemService+0xc9
c0100080 0012b8d8 ntdll!NtCreateFile+0xb
c0000000 00000000 KERNEL32!CreateFileW+0x343
1: kd> lmv m tsmlvsa
bff81000 bff987c0 tsmlvsa (no symbols)
Loaded symbol image file: tsmlvsa.sys
Image path: tsmlvsa.sys
Image name: tsmlvsa.sys
Timestamp: Thu Mar 18 06:18:51 2004 (40593F4B)
CheckSum: 0002D102
ImageSize: 000177C0
Translations: 0000.04b0 0000.04e0 0409.04b0 0409.04e0
Google search for tsmlvsa+0xfca3 fails but if we search just for tsmlvsa we get the first link towards problem resolution:
http://www-1.ibm.com/support/docview.wss?uid=swg1IC40964
- Dmitry Vostokov @ DumpAnalysis.org -