Trace Analysis Patterns (Part 260)
Saturday, June 27th, 2026Semantic Mapping is the trace and log analysis pattern where opaque runtime identifiers such as PIDs, TIDs, request IDs, handles, or session IDs are renamed or mapped to semantically meaningful diagnostic entities such as UI Thread, Worker Thread, Client Process, Blocking Thread, or Failed Request:
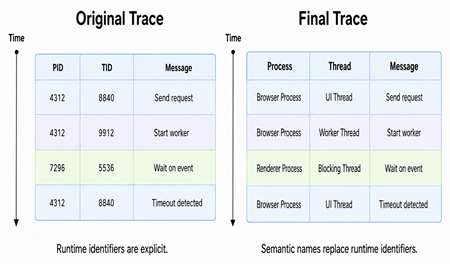
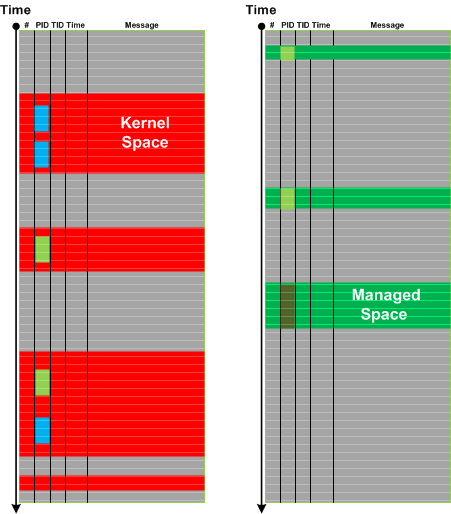
Additionally, in Semantic Mapping, we cannot only rename identifier values but also rename the Trace Schema itself, for example, changing column headers such as PID to Process and TID to Thread.
This analysis pattern differs from Trace Field, which is a mapping/function from trace messages to some other domain. It does not necessarily rewrite the trace presentation itself, but it may add additional ATID c to the Trace Schema. It is also different from Semantic Field, which is a semantic category/codomain/class into which trace messages are grouped, which is more about the meaningful domain of classification, not about rewriting trace labels. On the contrary, Semantic Mapping is a representation transformation that rewrites the trace into a more meaningful diagnostic form. It operates at two levels: instance level, renaming actual values, and schema level, renaming the fields/headers themselves.
Here is another example adapted to agentic AI:
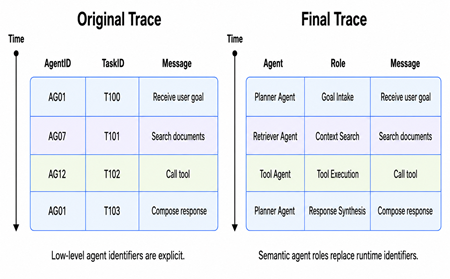
Using mathematical analogies, Semantic Mapping is essentially a readability-preserving isomorphism: the structural information is unchanged, but a human (or AI analyst) now works in a named, meaningful coordinate system rather than an anonymous numeric one.
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -