Archive for the ‘CDF Analysis Tips and Tricks’ Category
Wednesday, May 17th, 2017
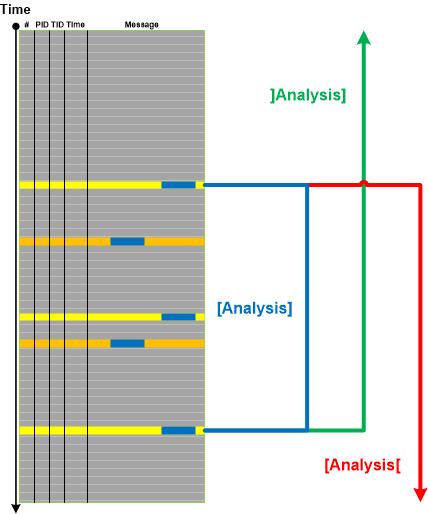
In order to perform Inter-Correlational analysis among traces and logs especially when we have Indexical Trace we need a dual operation: an ability to identify traces and Use Case Trails, and, if necessary, find their corresponding Braids of Activity in an index trace. Some data from the tracing domain or use case description may serve is Intrinsic ID. It can be itself some numeric ID, user or computer name.
A typical log analysis case from a distributed environment is illustrated on the following diagram:
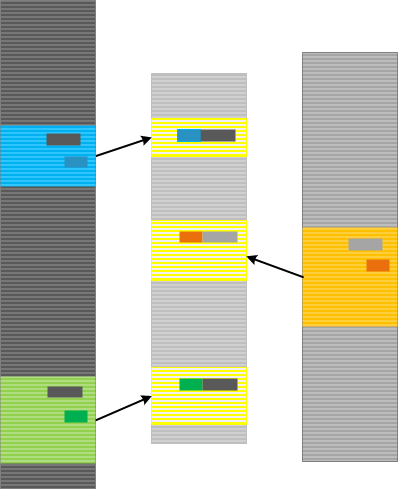
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Log Analysis, Software Trace Analysis Tips and Tricks, Software Trace Reading, Trace Analysis Patterns | No Comments »
Wednesday, May 3rd, 2017
Often, for Inter-Correlational trace and log analysis, we need to make sure that we have synchronized traces. The one version of Unsynchronized Traces analysis pattern is depicted in the following diagram where one trace ends (possibly Truncated Trace) before the start of another trace and both were traced within one hour:
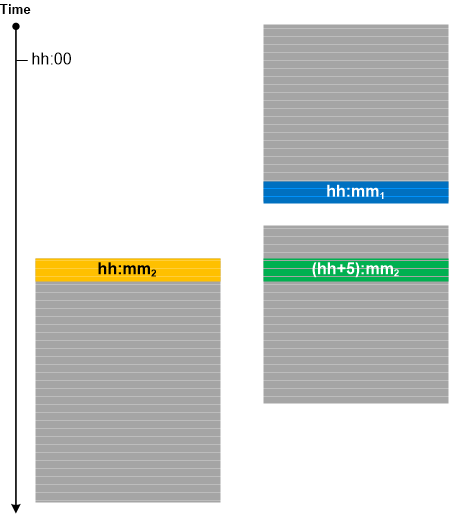
If tracing was done in different time zones with different local times specified in logs we can determine whether the traces are synchronized (when time zone information is not available in Basic Facts) by looking at minutes as shown for the third trace in the diagram above. This technique can also be used in trace calibration (see Calibrating Trace).
There is a similar analysis pattern for memory analysis called Unsynchronized Dumps.
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Core Dump Analysis, Crash Dump Analysis, Crash Dump Patterns, Log Analysis, Software Trace Analysis, Software Trace Analysis Tips and Tricks, Software Trace Reading, Trace Analysis Patterns | No Comments »
Tuesday, February 7th, 2017
One of the trace attributes we didn’t pay much attention to in the past is CPU. This column is present in some ETW-based trace implementations such as Citrix CDF traces. As any trace attribute, it can be used to form Adjoint Thread of Activity (as all messages from code executed on that particular CPU). As we already considered threads as braids, we use braid groups as a further metaphor. In our case we combine CPUs and threads into one group which uses permutation for CPU scheduling. Instead of permutations, twists may be modeled as changes of threads. The Braid Group analysis pattern is illustrated in the following diagram:
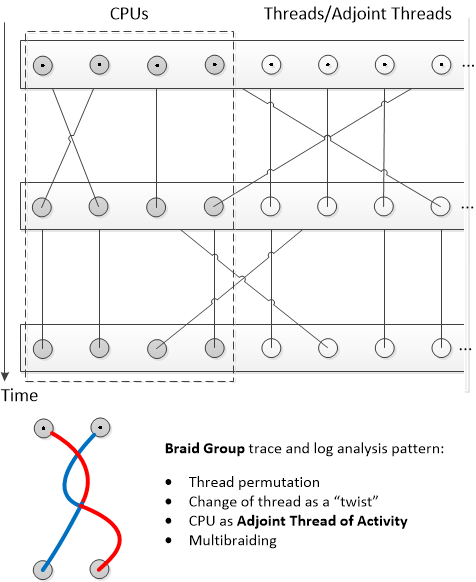
This is a preliminary description of the analysis pattern. We plan to elaborate on it in further case studies. For example, instead of multithreading we can use multibraiding.
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Log Analysis, Software Trace Analysis, Trace Analysis Patterns | No Comments »
Tuesday, November 15th, 2016
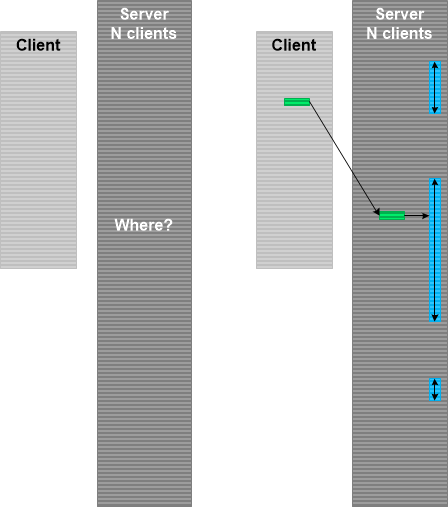
When we have hundreds of separate trace files from Split Trace and a smaller Split Trace with fewer files or just a single trace file that was recorded simultaneously (for example, a client from client-server environment) we can “project” the smaller Message Space into the larger Message Space as depicted in the following diagram:
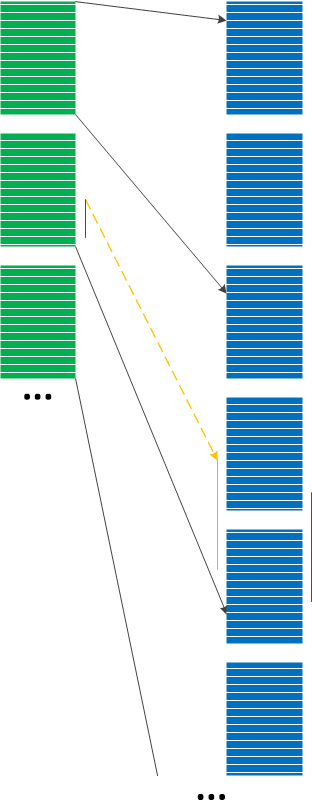
This Projective Space analysis pattern can be used in conjunction with Indexical Trace where time interval can be used as an index into the larger Split Trace. Such projection may not be accurate but, assuming that the target trace Statement Current is uniform on average, can still be a very good heuristic instead of a binary search. For example, recently we had 4 sequential trace files for the client and 36 sequential files for the server. The software problem interval was specified in Basic Facts. We found that it in the second path of the 4th client trace. We, therefore, only inspected the last 4 traces of the 36 server sequential trace set and found it contained in the 35th server trace.
This pattern uses projective space metaphor from mathematics.
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Log Analysis, Software Trace Analysis, Trace Analysis Patterns | No Comments »
Wednesday, June 29th, 2016
When using complex trace and log analysis patterns such as Fourier Activity we may be first interested in selecting all instances of a particular message type from specific Thread of Activity and then look for Time Deltas, Discontinuities, Data Flow, and other patterns. We call this analysis pattern Fiber of Activity by analogy of fibers (lightweight threads) since the individual thread execution flow is “co-operative” inside, whereas threads themselves are preempted outside. The following diagram from Fourier Analysis example illustrates the concept by showing three fibers:
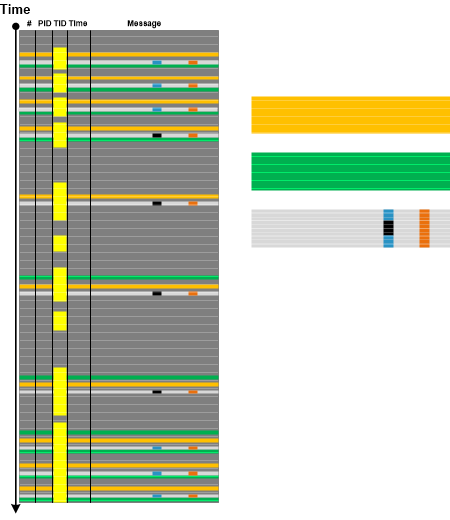
This analysis pattern is different from trace-wide Sheaf of Activities where the latter is about selecting messages as Adjoint Threads of Activity which may span several processes and threads.
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Log Analysis, Software Trace Analysis, Trace Analysis Patterns | No Comments »
Monday, June 27th, 2016
Sometimes we have trace and log messages that appear with certain time frequency throughout all log or specific Thread of Activity. Such frequencies may fluctuate reflecting varying system or process performance. Analyzing trace areas where such messages have different Time Deltas may point to additional diagnostic log messages useful for root cause analysis. The following minimal trace graph depicts the recent log analysis for proprietary file copy operation where the frequency of internal communication channel entry/exit Opposition Messages was decreasing from time to time. Such periods were correlating with increased time intervals between “entry” and “exit” messages. Analysis of messages between them revealed additional diagnostic statements missing in periods of higher frequency and corresponding Timeouts adding up to overall performance degradation and slowness of copy operation.

Additional analysis of Data Association in a different message type between available communication buffers and the total number of such buffers revealed significant frequency drop during constant Data Flow of zero available communication buffers:
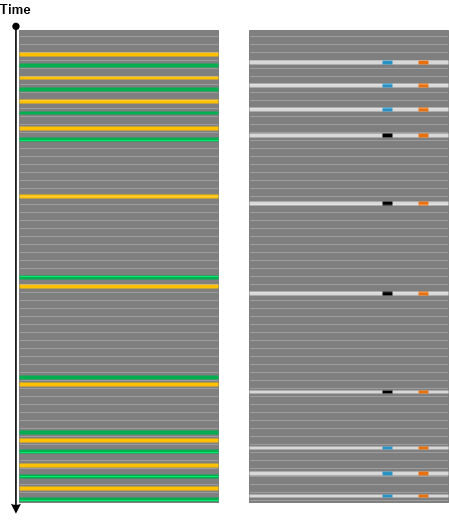
We call this analysis pattern Fourier Activity by analogy with Fourier series in mathematics. This pattern is for individual message types and can also be considered a fine-grained example of Statement Current and Trace Acceleration analysis patterns which can be used to detect areas of different frequencies in individual Fibers (Adjoint Threads of Activities formed from the same Thread of Activity).
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Log Analysis, Root Cause Analysis, Software Trace Analysis, Trace Analysis Patterns | No Comments »
Saturday, April 30th, 2016
Trace Extension is an obvious log analysis pattern that is about trace messages that refer to some other trace or log that may or may not exist. Sometimes, there can be instructions to enable additional tracing that is not possible to cover by the current trace source. We have seen this in some trace statements from .NET Exception Stack Traces.

- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in .NET Debugging, CDF Analysis Tips and Tricks, Log Analysis, Software Trace Analysis, Software Trace Reading, Trace Analysis Patterns | No Comments »
Saturday, March 12th, 2016
Data Selector is a variant of Inter-Correlation trace analysis pattern where we use data found in one trace to select Message Set or Adjoint Thread of Activity in another trace. This analysis activity is depicted in the following picture where we have a client log and corresponding server log. In the server log we have log entries for many client sessions. To select messages corresponding to our client session we use some data attribute in the client trace, for example, the user name, and Linked Messages analysis pattern to find one of the messages in the server log that contains the same user name. Then we find out which user session it belongs to and form its Adjoint Thread:
This pattern is different from Identification Messages where we don’t even know the object that emitted trace messages. In Data Selector case we know in principle what kind of messages we are looking for. We just need to select among many alternatives.
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Log Analysis, Software Trace Analysis, Trace Analysis Patterns | No Comments »
Saturday, January 30th, 2016
Often, we need to identify the source of messages based on problem object or subsystem description (what question) before we proceed answering where question (where in the trace we can find messages related to the problem). Even when we know where are messages there can be many sources to select from (if we don’t know the where question we can use Indirect Message analysis pattern). To answer what question we propose Identification Messages analysis pattern. Basic Fact problem description may include properties and behavioural description of the problem object or subsystem. Based on that we can map them to the log messages that such an object can produce:
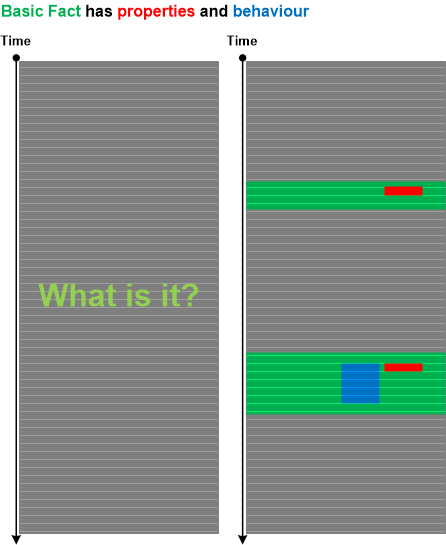
These messages may not be Error Messages or some other type of messages reflecting abnormal behavior. These messages are only used to identify the software object, module or subsystem.
For example, in one case there were problems with the custom status bar. However, the window handle for it or its parent wasn’t specified in the problem report. In the log file we had a lot of messages describing GUI behavior of many windows. To find out the status bar we thought that it should have small height but long width. Indeed we found one such child window. In addition, for this window the log file contained many messages related to frequent window text changes, possibly reflecting the status bar updates. Having identified the window handle, we proceeded to the analysis of another log with thousands of window messages. Because of the known window handle we were able to select only messages pertaining to our problem status bar.
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Log Analysis, Software Trace Analysis, Software Trace Reading, Trace Analysis Patterns | No Comments »
Saturday, January 16th, 2016
When we have very large traces and Basic Facts containing some data values such as a user name, device name, or registry key value we may use Data Interval analysis pattern to select the trace fragment for the initial log analysis. The first and the last trace messages containing selected data for the closed Data Interval. Depending on the trace size and other considerations we can also choose open Data Intervals. It is illustrated in the following diagram where we use Analysis interval notation borrowed mathematics:
Interval boundary messages may also be used as Trace Mask for another trace.
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Log Analysis, Software Trace Analysis, Trace Analysis Patterns | No Comments »
Saturday, November 14th, 2015
Multiple traces and logs are usually collected for diagnosing distributed systems. Different tools and tracing settings (circular, sequential, file size limit) may be used, systems may be unsynchronized, and individual system tracing may be started at different times due to manual tracing setup and switching between systems. There may be Blackouts, Circular, and Truncated traces. When we analyze such a trace set (Inter-Correlation) we usually select one trace or log that is used as Calibrating Trace. It is used for measuring all other traces against Basic Facts such as start and end tracing times, and the time of the problem. One such scenario is illustrated in the following diagram:
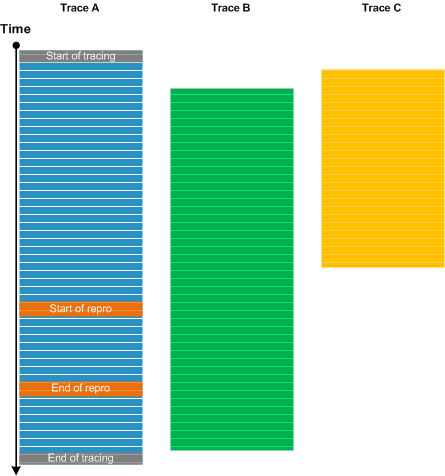
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Log Analysis, Software Trace Analysis, Trace Analysis Patterns | No Comments »
Tuesday, November 10th, 2015
We would like to introduce Trace Dimension pattern to address the emerging complexity of logs from distributed environments. By a distributed environment we mean not only a collection of multiple computers (for example, client-server) but also terminal services environments with several different user sessions on one computer (OS) and even multiple user processes (IPC) in some cases. If some task can be performed on one machine or session or inside one process then splitting it across several computers, sessions, or processes usually results in logs with added Distributed Infrastructure Messages (DIMs) such as from proxies, channels and their management:
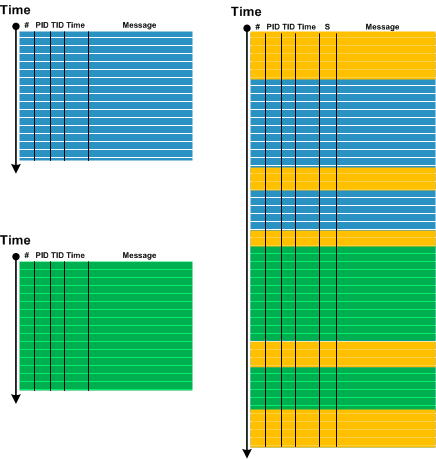
So, one of the trace simplification strategies is to request the reproduction and its tracing in a simplified environment (such as inside one terminal services session) to eliminate DIMs. In one case, we analyzed a trace for a clipboard paste problem in Windows terminal services environment. After a clipboard copy different data was pasted to different applications. The same behavior was observed for application processes running inside different sessions and processes running inside one session. However, the log was collected for the more complex multiple session scenario with many False Positive Errors which completely disappeared from one session scenario log.
DIM abbreviation played a role in naming this pattern. Additionally, if sessions can be considered a second dimension, then separate VMs can be considered as a third dimension, separate clouds as a 4th dimension, and so on.
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Log Analysis, Software Trace Analysis, Trace Analysis Patterns | No Comments »
Wednesday, September 30th, 2015
Sometimes we have Periodic Message Blocks of a few adjacent messages, for example, when flags are translated into separate messages per bit. Then we may have a pattern of Sequence Repeat Anomaly when one of several message blocks have missing or added messages compared to the more numerous number of expected identical message blocks. Then Missing Message Message Context may be explored further. The following diagram illustrates the pattern:
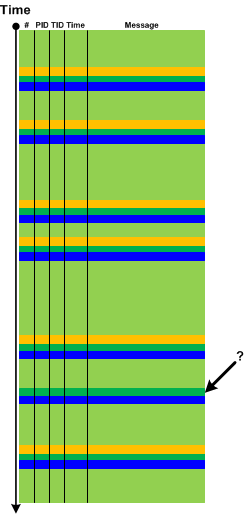
The name of the pattern comes from the notion of repeated DNA sequences.
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Log Analysis, Software Trace Analysis, Software Trace Analysis and Genetics, Software Trace Analysis and Genomics, Software Trace Reading, Trace Analysis Patterns | No Comments »
Monday, July 6th, 2015
Sometimes we have messages that report about error but do not give exact details. For example, “Communication error. Problem at the server side” or “Access denied error”. This may be the case of Translated Messages. Such messages are plain language descriptions or reinterpretations of flags, error and status codes contained in another log message. These descriptions may be coming from system API, for example, FormatMessage from Windows API, or may be from custom formatting code. Since the code translating the message is in close proximity to the original message both messages usually follow each other with zero or very small Time Delta, come from the same component, file, function, and belong to the same Thread of Activity:
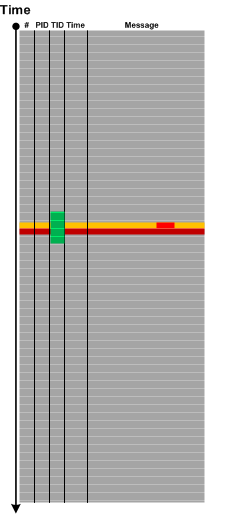
This pattern is different from Gossip because the latter messages come from different modules, and, although they reflect some underlying event, they are independent from each.
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Software Trace Analysis, Software Trace Reading, Trace Analysis Patterns | No Comments »
Monday, June 29th, 2015
Message stream can be considered as a union of Message Spaces. A message space is an ordered set of messages preserving the structure of the overall trace. Such messages may be selected based on a memory space they came from or can be selected by some other general attribute, or a combination of attributes and facts. The differences from Message Set is that Message Space is usually much larger (with large scale structure) with various Message Sets extracted from it later for fine grained analysis. This pattern also fits nicely with Adjoint Spaces. Here’s an example of kernel and managed spaces in the same CDF / ETW trace from Windows platform where we see that kernel space messages came not only from System process but also from other process contexts:
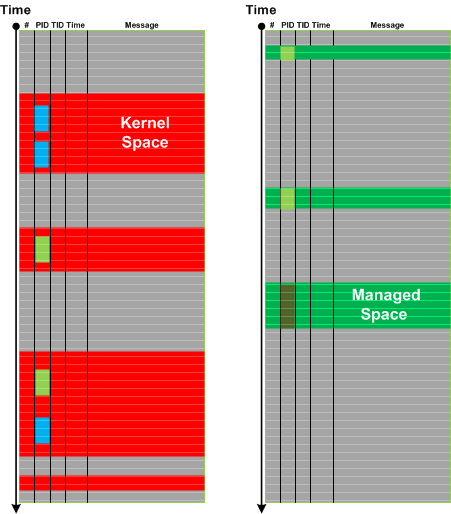
In the context of general traces and logs such as debugger logs separate Message Space regions may be linked (or “surrounded”) by Interspace.
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Software Trace Analysis, Software Trace Reading, Software Trace Visualization, Structural Trace Patterns, Trace Analysis Patterns | No Comments »
Sunday, May 3rd, 2015
If you analyze ETW-based traces such as CDF you may frequently encounter No Trace Metafile pattern especially after product updates and fixes. This complicates pattern analysis because we may not be able to see Significant Events, Anchor Messages, and Error Messages. In some cases we can recover messages by comparing Message Context for unknown messages. If we have source code access this may also help. Both approaches are illustrated in the following diagram:
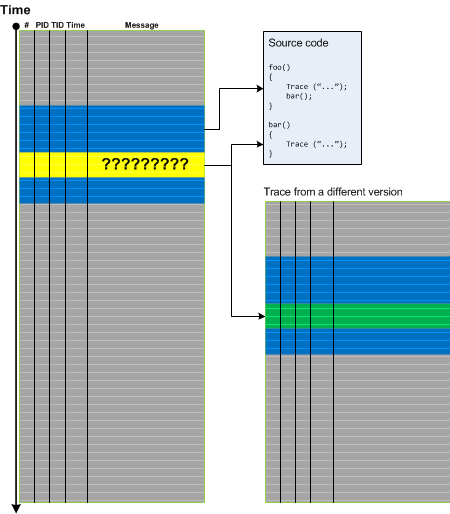
The same approach may also be applied for a different kind of trace artifacts when some messages are corrupt. In such cases it is possible to recover diagnostic evidence and, therefore, we call this pattern Recovered Messages.
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Software Trace Analysis, Software Trace Analysis Tips and Tricks, Software Trace Reading, Trace Analysis Patterns | No Comments »
Saturday, March 14th, 2015
Sometimes we have a uniform stream of messages that belong to some Activity Region, Thread of Activity, or Adjoint Thread of Activity. We can use micro-Discontinuities to structure that message stream into groups of actions, for example, Macrofunctions, especially if semantics of trace messages is not yet fully clear to us. This may also help us to recognize Visitor trace. Originally we wanted to call this pattern Micro Delays, but, after recognizing that such delays only make sense for one activity (since there can be too many of them in the overall log), we named this pattern Punctuated Activity. Usually such delays are small compare to Timeouts and belong to Silent Messages.

- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Software Trace Analysis, Software Trace Analysis Tips and Tricks, Software Trace Reading, Trace Analysis Patterns | No Comments »
Sunday, February 22nd, 2015
Sometimes we have Basic Facts in a problem description but can’t find messages corresponding to them in a trace or log file but we are sure the tracing (logging) was done correctly. This may be because we have Sparse Trace, or we are not familiar well with product or system tracing messages (such as with Implementation Discourse).

In such a case we for search for Indirect Message of a possible cause:

Having found such a message we may hypothesize that Missing Message should have located nearby (this is based on semantics of both messages), and we then explore corresponding Message Context:

The same analysis strategy is possible for missing causal messages. Here we search for effect or side effect messages:

Having found them we proceed with further analysis:

- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Log Analysis, Software Trace Analysis, Software Trace Analysis Tips and Tricks, Trace Analysis Patterns | No Comments »
Saturday, January 31st, 2015
Sometimes we need memory reference information not available in software traces and logs, for example, to see pointer dereferences, to follow pointers and linked structures. In such cases memory dumps saved during logging sessions may help. In case of process memory dumps we can even have several Step Dumps. Complete and kernel memory dumps may be forced after saving a log file. We call such pattern Adjoint Space:
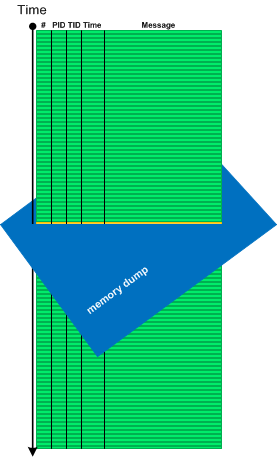
Then we can analyze logs and memory dumps together, for example, to follow pointer data further in memory space:
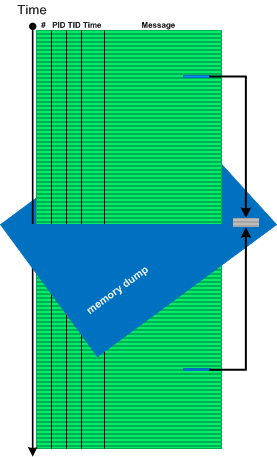
There is also a reverse situation when we use logs to see past data changes before memory snapshot time (Paratext memory analysis pattern):
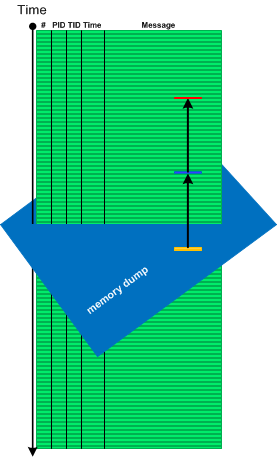
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Core Dump Analysis, Crash Dump Analysis, Crash Dump Patterns, Debugging, Log Analysis, Software Trace Analysis, Software Trace Analysis Tips and Tricks, Software Trace Reading, Trace Analysis Patterns | No Comments »
Saturday, January 24th, 2015
Sometimes specific parts of simultaneous Use Case Trails, blocks of Significant Events or Message Sets in general may overlap. This may point to possible synchronization problems such as race conditions (prognostics) or be visible root causes of them if such problems are reported (diagnostics). We call this pattern Activity Overlap:

For example, a first request may start a new session and we expect the second request to be processed by the same already established session:
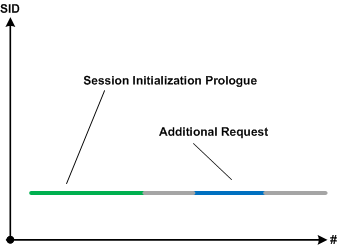
However, users report the second session started upon the second request. If we filter execution log by session id and do Intra-Correlational analysis we find out that session initialization prologues are overlapped. The new session started because the first session initialization was not completed:
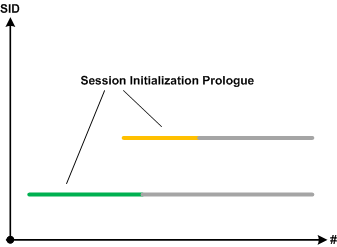
- Dmitry Vostokov @ DumpAnalysis.org + TraceAnalysis.org -
Posted in CDF Analysis Tips and Tricks, Debugging, Log Analysis, Software Prognostics, Software Trace Analysis, Trace Analysis Patterns | No Comments »